 Parker McKee
Parker McKeeAn autonomous car is flawlessly navigating around the streets of Arizona when suddenly, it appears to miss an obvious stop sign, barrels through a 4-way stop, and crashes into a car crossing from another direction. The cause? A bad actor placed a patch and a saran like filter over the sign. Human eyes could easily tell it was a stop sign, but to the Deep Neural Net (DNN), the sign was classified as a bird sitting on the side of the road. This is just one example of the vulnerabilities that today’s AI models contain.
The term AI is thrown around liberally, and thought of as “ultra smart”, in reality, this may be very far from the truth. The rebirth of deep learning in 2011, coupled with access to cheap compute and growing availability of datasets, catalyzed AI’s penetration into organizations of all shapes and sizes. Whether it be facial recognition to seamlessly move through customs, voice recognition to access your bank account or object classification to recognize a stop sign in a self-driving car, society is trusting an ever-growing task load on systems that may not be all that secure. This notion is gaining more traction, as numerous academic papers seek to highlight many of the ways in which classifiers can be tricked and manipulated.
Attacks on Deep Neural Nets (DNNs) come in varying types, including object rotation, invisible noise injection, patch placement, altered texture, or adjusted lighting to name just a few. In a recent paper titled “Adversarial Patch” out of Google, a group of researchers found they could confound a classifier by presenting a printed patch to any scene. The patches were so effective, they caused the classifiers to ignore all other items in the state space and output the classification their patch was optimized for. In the example below, you can observe how placing a patch next to the banana caused a near 100% classification as a toaster.

In the examples above, humans can still distinguish the original object easily, however, the adversarial patch confuses the DNN due to its lack of robustness. In the case of patch placement, the clear visibility of the patch allows humans to more easily identify potential tampering in an attack. Alternative adversarial methods though, like noise injection, prove far more challenging to discern.
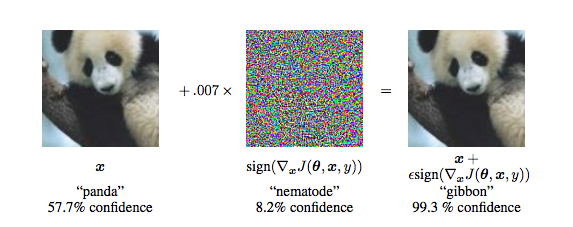
In a separate paper out of Google Research research titled, “Explaining and Harnessing Adversarial Examples”, it was found that adding an imperceptibly small vector to an image could change its classification in an undetectable fashion to human senses. As you can see in the examples below, injecting just a small amount of well-constructed noise onto the image of a panda, led to the classifier thinking it was a gibbon, with 99.3% confidence. The most critical point to note here is that in the image on the right, the injected noise is largely undetectable to human eyes.
While the practice of tricking classifiers with adversarial attacks isn’t novel, the ability to do so in a controlled fashion undetectable to human sight is significantly more challenging. The mastery of this practice will likely lead to many novel fraudulent attacks over the coming decade. I’ve included a few potential examples below.
Facial Recognition Isn’t Stopping This Bad Guy From Entering The Country:
A fugitive wants to enter Australia through a legal customs checkpoint without getting caught. The criminal acquires a stolen passport on the dark web and designs an adversarial patch to wear on his cheek. This patch confounds the classifier into thinking he is the same person as the man in the stolen passport photo. Everything checks out and the man seamlessly enters the country before anyone notices what has occurred.
Get That Resume Placed in The READ Pile:
A Fortune 500 company gets 20,000 applications per year. In an effort to only meet the best applicants, they use AI to sort for a few variables. (GPA/SAT/ect..) The “best” applications get read by a human and in many cases invited for an interview. Frustrated by a lack of responses, a candidate hires a bad actor to create an adversarial version of his resume that reads honestly to the human eye, but to a classifier shows perfect test scores, a 4.0GPA, and a prior job at Google (none of these are true). The candidate gets the interview because the AI places his resume in the read pile.
How does this work, one might wonder? The answer lies in the way neural networks are constructed. Deep neural networks don’t look at a stop sign and see a stop sign, instead, they see a massive matrix with millions of dimensions. The networks have a set of configuration variables (“parameters”) which are optimized to try and predict the right output. When an adversarial input comes in with altered data, the alteration can be made in a small part of the matrix that would be undetectable to a human. Despite this tiny change, the resulting behavior of the network can be dramatic. If the adversarial attack was successful, the computed output can be anything the attacker wants.
Tricking a classifier with an adversarial input has become a more normalized practice. The challenge of successfully pulling off one of the attacks described above is found not just in tricking the classifier but tricking it to see your desired output. In many cases, perpetrators don’t have access to the models themselves and must work through a trial and error process to back into their desired classification. Despite the challenges in building such adversarial attacks, we’ve begun to see new novel protection approaches anticipating what threats are forthcoming. From noise detection systems to more accurate mathematically certifiable AI frameworks, we have seen innovation and many opportunities in this space.
Over the coming months and years, more cybercriminals will begin to utilize the vulnerabilities of DNNs to facilitate their attacks. With this in mind, we’re continually looking to meet innovators building novel approaches to AI that solve these adversarial weaknesses. If you’re working on solving problems in this space, we’d love to connect.
Sources:
–https://www.zdnet.com/article/googles-best-image-recognition-system-flummoxed-by-fakes/
–https://arxiv.org/pdf/1412.6572.pdf
–https://arxiv.org/pdf/1312.6199.pdf
-https://arxiv.org/pdf/1712.09665.pdf